Key Concepts for Data Contributors
In this section, you will learn about the key concepts and relationships in the FaceBase database, vocabulary terms used to label data in FaceBase, and the supported data types and file formats. If you are planning to submit data to FaceBase, see our listing of currently supported Experiment Types. Please contact us if you do not see your experiment type on the list.
Note that FaceBase is designated by NIH as an NIH-Designated Genomic Data Repository. Please see Guidelines for Submitting Controlled Access Data for details, particularly relevant if you need to satisfy a journal’s data-sharing repository requirement.
Contents
- Database Structure
- Vocabulary
- Data Types and File Formats
- References to External Data and Visualization
Database Structure
The following diagram depicts the structure of the FaceBase database.
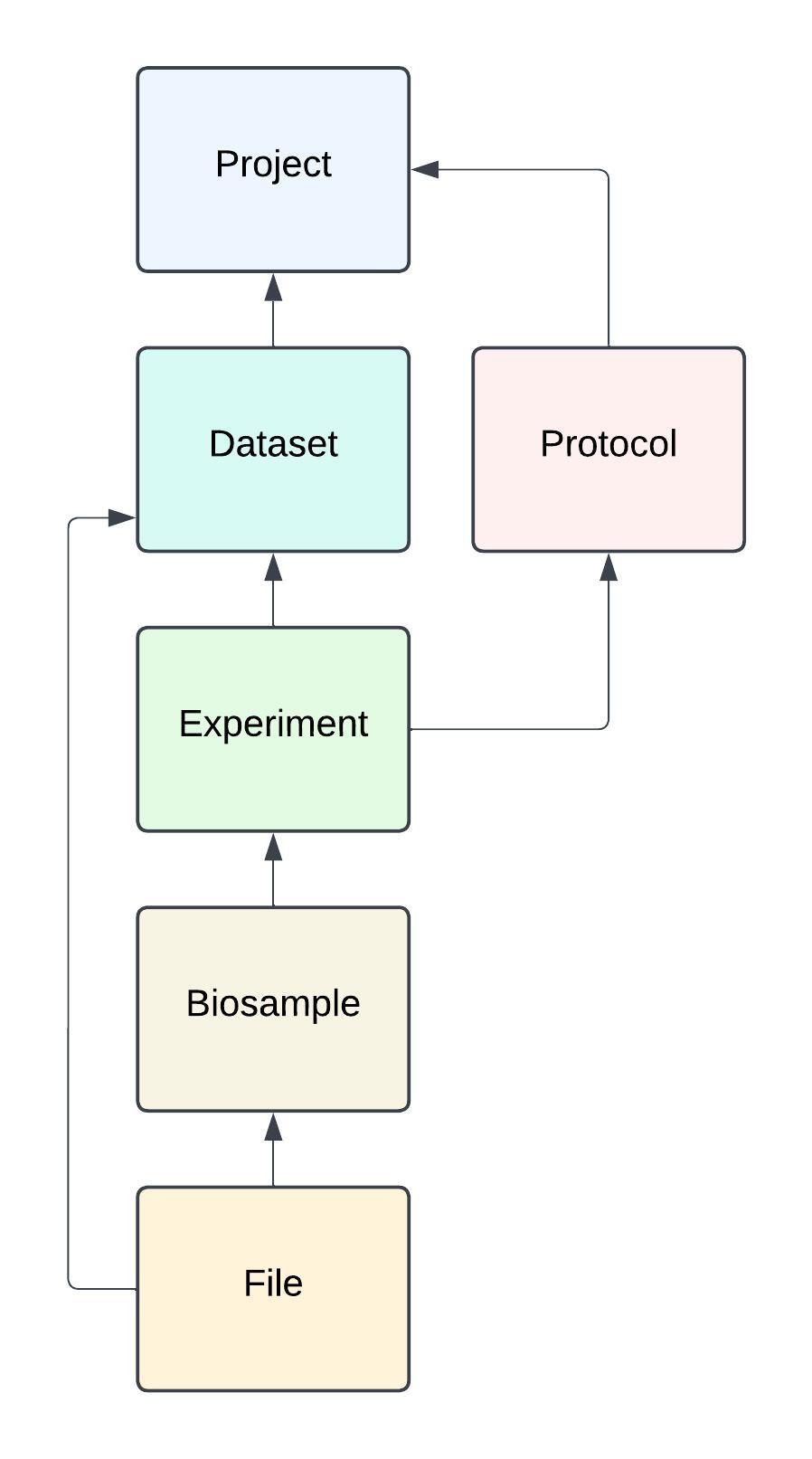
-
Project: represents a research project (e.g., a R01 investigation, etc.). Projects include a set of project investigators and project members (not depicted).
-
Dataset: represents a unit of data collected and submitted to the FaceBase site. Typically, a dataset represents a whole or a logical unit of an investigation (i.e., a study within an overall investigation/project).
-
Protocol: represents the documentation for the research protocol and should include sufficient details to reproduce the results of the experiment. The details may be entered in a rich text editor (online), attached as a file, or may reference a published protocol. We recommend following the Nature Protocol Exchange or similar guidelines for documenting protocols.
-
Experiment (a.k.a., assay): represents an experiment at a fine-grained unit of detail. It is intended to broadly cover multiple “bioinformatics” (i.e., sequencing or microarray) and imaging (i.e., various forms of microscopy) assay types. An experiment will generally be conducted on multiple biological samples. An experiment may reference another experiment as its control.
-
Biosample: represents the biological sample used in a study. There may be many biosamples in a dataset and biosamples are generally grouped together and associated with an Experiment as a collection of biological replicates. Note that FaceBase does not collect physical tissue samples. The ‘biosample’ here is only the metadata used to describe the physical samples used in your experiments.
-
File: represents the data file produced by the experimental or analytic procedures of the experiment. Files may be linked to biosamples to indicate more precisely the provenance of the data file. See data types and file formats for more details.
Vocabulary
In order for your data to best reusable and interoperable with other data, it is important to label them with shared terminology broadly understood by other researchers. FaceBase has adopted external, standardized “vocabulary” a.k.a. “ontology” for most terminology wherever possible. If you cannot find a term that you need in order to describe your data, please contact us. To search for terms not already available in FaceBase, see the NCBO BioPortal.
Currently, we use the following vocabulary:
| Category | Source(s) | Available on FaceBase |
|---|---|---|
| Anatomy | UBERON, OCDM | View online |
| Data Use (DUL) | NIH | View online |
| Diagnosis | FaceBase | View online |
| Ethnicity | NIH | View online |
| Experiment Type | OBI | View online |
| Gene | NCBI Gene | View online |
| Genotype | FaceBase | View online |
| Phenotype | MP, HPO, OCDM | View online |
| Race | NIH | View online |
| Sex | UBERON | View online |
| Species | NCBI Taxonomy | View online |
| Stage | Varies by species | View online |
| Strain | MGI | View online |
| Syndrome | MONDO | View online |
| Treatment | FaceBase | View online |
When a needed term is not available in the standard vocabulary, we will work with data submitters to create a new term on FaceBase and promote it to the appropriate upstream vocabulary maintainers for future standardization.
Data Types and File Formats
Most studies will produce one or more of the following types of data. We are always open to discussing additional data types and formats, if they can be of value to our research community. We accept data formats that are “open” (either a formal or de facto standard) and for which free or widely used tools are available for using the data files.
- Sequencing Data: “raw” sequencing data (fastq files). These must be gzipped and use the ‘.fastq.gz’ file extension. If you use the common naming scheme to indicate the sequence read number, ‘example_1.fastq.gz’ or ‘example_R2.fastq.gz’, the system will automatically extract the read number from the file name.
- Spatial Genomics Data: all raw data. The raw data comes in two folders: Basic Results with raw data for bioinformatics analysis (.csv files) and Mini Project with raw data for interactive visualization. The processed data can be saved in .h5ad (Python package) or .rds (R package) files using the three .csv files from the Basic Results Folder. (Based on the Spatial Genomics, Inc. platform but we can accomodate other platforms.)
- Processed Data: data that are derived from sequencing data through a particular pipeline. Usually fastqc reports (.fastqc.tgz or .fastqc.zip), count files (.count, .tpm, .fpkm), measures in tab-separated format (.tsv), and of course alignment mapping files (.bam) and indexes (.bam.bai).
- Track Data: data that are derived from sequencing or processed data and used in genome browsers, such as BED (.bed), bigBed (.bb), and bigWig (.bw) files. Use binary formats (bigBed and bigWig) if you would like them available for online visualization.
- Microarray Data: “raw” microarray data (CEL files). These must be gzipped and use the ‘.CEL.gz’ file extension.
-
Imaging Data: high-resolution 3D or 2D imaging data, such as micro-CT accepted in NIfTI format gzipped (.nii.gz) or DICOM (.dcm), confocal or other microscopy sources in TIFF or OME-TIFF (.tiff or .ome.tiff), and other sources in JPEG (.jpg or .jpeg). Other formats may be considered on an as needed basis. When it comes to microscopy, we understand that proprietary file formats are the norm. As stated above, we accept files that can be open and read with widely used tools. To test if your data are acceptable for submission, we recommend tht you test if you can use them with ImageJ, Fiji, or Bioformats.
For CT data submitted as DICOM, we strongly prefer multi-frame DICOM, where all slices of a scan are consolidated into a single file. If your scanner only produces single-frame DICOM (a separate file per slice), we will ask you to zip up all the files belonging to each logical scan before submission. Note that even zipped, single-frame DICOM is a sub-optimal format for downstream (re)users of the data, so multi-frame DICOM is always the better choice when your equipment supports it.
- Surface Model / Mesh Data: 3D surface models (a.k.a., “polygon mesh” files) that are generally derived from hard tissue imaging data. Currently, we accept Wavefront (OBJ), Polygon File Format (PLY), and Stereolithography (STL), as these are all open formats that are widely used and supported by common tools. For OBJ, we prefer that OBJ files be gzipped (.obj.gz) as it reduces the storage size and more importantly the load time for online visualization. If you want these files to be visible online in the online mesh viewer, you should limit the size of any model (which may include multiple mesh files) to under 10 MB. The entire model must be downloaded to the user’s browser in order to view, and therefore larger models can be prohibitively time consuming to download for users on slower networks. Multiple mesh data entities can be associated with each imaging data entity.
- Thumbnails: smaller images that give a representation of imaging data. FaceBase will attempt to generate thumbnails of your uploaded image files and will display them along with your downloadable files. You may also upload thumbnails on your dataset page itself as a preview for users to learn more about your data before downloading any files.
- Videos: videos can be very useful to help as visualization aids (e.g., to complement a Z stack of microscopy images). If possible, please use the open standard MPEG-4 (.mp4) format.
- Other: additionally, you may share documents, spreadsheets, and other types of data files that were generated from your study.
For a complete listing of our most current recognized data types and formats consult the following:
References to External Data and Visualization
For some types of Datasets, such as Genome Wide Association Studies (GWAS), it may be appropriate to include references to external sources of data and visualization. For example, a GWAS study may have produced or reused genomic data submitted to dbGaP, in addition derived results would have been generated from the original data, and the derived data may have been submitted to LocusZoom for online visualization. In cases such as these, you should enter a Dataset with a clear Description of the data and a thorough Study Design. You should provide accession numbers to data at external repositories (e.g., dbGaP) and Web references to the visualizations of your data using the [label](url) syntax available in the Description field; e.g., [View results for ABC](https://example.org/to/abc). By following these guidelines, users of your data will be able to find your datasets on FaceBase and then navigate to the visualization interface for your data.
Next step, Data Submission Process.